scrapy
创建一个scrapy工程 scrapy startproject 工程名
生成一个爬虫程序 scrapy genspider 爬虫名 爬虫域名
执行爬虫 scrapy crawl 爬虫名
scrapy 调试平台 scrapy shell1
2
3
4
5
6
7Windows 装 scrapy
一.pycharm直接装,装不了用第二种
二. 1>pip install wheel
2>pip install pywin32路径
3>pip install Twisted路径
4>pip install scrapy
linux 和 macOS 安装 pip install scrapy
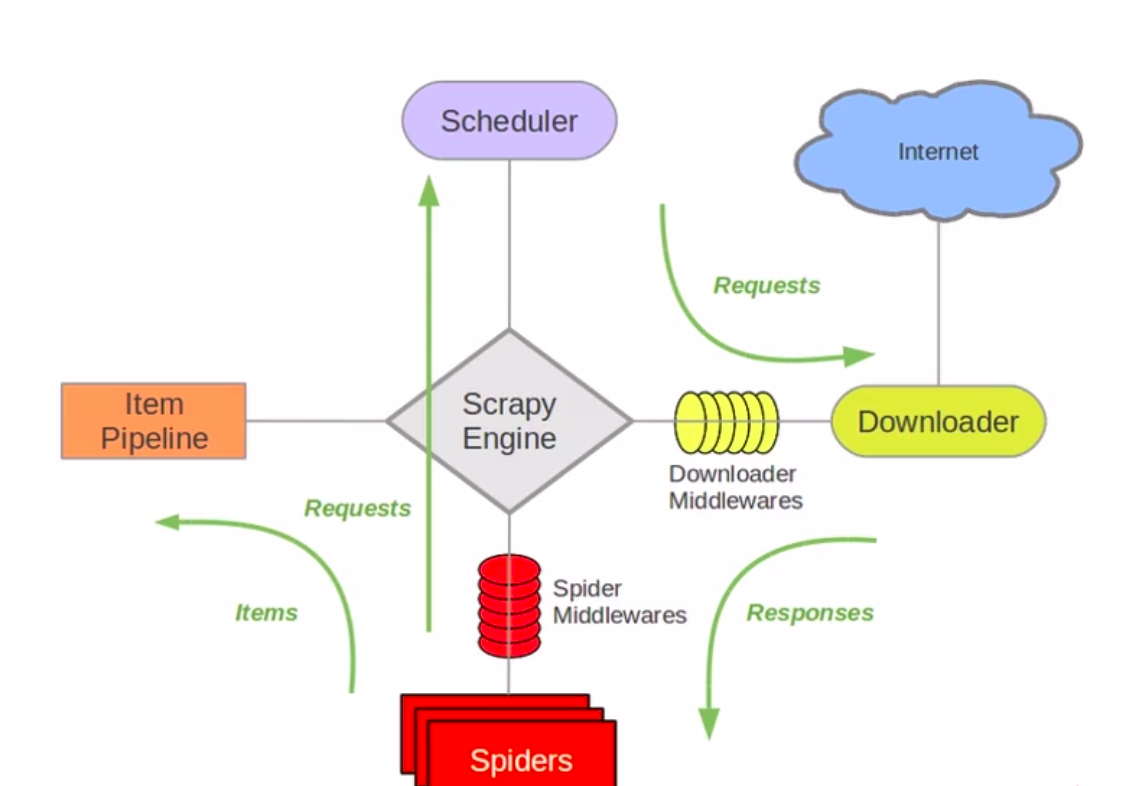
scrapy 架构图
散点知识:
schedular封装的Request包含url和方法,默认方法为parse,具体写的通过callback调用,通过yield返回给schedular
parse包含参数self和response
response只有body和text,没有content
使用xpath匹配直接response.xpath(‘ ‘)
选择器通过extract()获取data里面的数据,形成一个列表,若只有一个通过extract()[0]或者extract_first()
scrapy拼接url: response.urljoin(‘不完善的url’) 不同于urllib无需基础的url
scrapy框架中的item和pipline,item是一种简单的容器,保存了爬取到的数据(类似于字典) pipline:主要是对收到的item进行处理[实现存储\清洗….]
yield 返回item则将item里面的数据传给piplines进行后续处理 ,返回request则给schedular处理(封装了request和url)
scrapy在response中间传递数据主要用到response.meta,存储的位置叫response.meta(存储的形式为字典的格式) yield 过后就会传递过去1
2
3
4response.meta['chapter'] = 1
req = scrapy.Request(url=next_page, callback=self.parse)
req.meta['chapter'] = response.meta['chapter']
yield req
scrapy 数据流
- start_urls 或 start_requests, 通过上面两个内容可以生成 Request(url 函数),
这些 Request 被发送到 Engine 中. - Engine 会将 Request 放入 Scheduler 保存, 等待下载器空闲
- 在下载器空闲的时候, Engine 会从 Scheduler 中获取 Request, 传递给 Downloader
- 传递 Request 到 Downloader 的过程中, 会经过 Downloader Middleware(process_request)
- 执行下载后, 会生成 Response, 返回给 Engine, 过程中会经过 Downloader Middleware
(process_response) - Engine 会将获取到的 Response 返回给 Spiders, 这之中会经过 Spider Middleware
(process_spider_input) - Spiders 会将 Response 获取具体的信息, 生成新的 Request 或者是 Item,
Spiders 会将 Request/Item, 返回给 Engine. 这之中会经过 Spider Middleware
(process_spider_output) - Engine 会判断 Request 或者是 Item, 如果内容是 Request, 存储到 Scheduler 中,
如果是 Item, 发送到 Item Pipeline 中继续处理 - 循环第三步