to_dict(将dataframe转换成字典格式)===对应的为json格式(十分常用)
常用的有records和index
1 | import pandas as pd |
次要的有dict(默认)\list\series\split都必须掌握
1 | import pandas as pd |
astype(强制数据类型转换)
1 | df['A'] = df['A'].astype(float) |
group_by(分组)
1 | (如果groupby后并sum,如果存在数字求和,则其他类型组合会清除,如果不存在数字求和,则字符串会出现拼接效果,如下所示)====通常的group都是与apply一起使用的,需要进一步了解 |
map\applymap\apply用法
1 | map===将series中的每一个元素通过函数进行处理(常用于dataframe中数据某一个字段整体的清洗) |
dataframe索引操作
reset_index
1 | 重置行索引(若果不加drop=True,则原来的索引成为新的列,加上则替换原索引) |
reindex
1 | 重构或者任意重排索引,没有的数据会显示nan |
rename
1 | df.rename(columns=lambda x: x + 1):批量更改列名 |
数据处理相关
fillna补值
1 | #直接替换原数据的nan为0,不加inplace不对原数据操作 |
dropna删除空值
1 | df.dropna(how='') all删除全为空值那一行,any删除存在空值那一行(默认0表示行,1代表列) |
unique去重(针对series的去重)
1 | df['A'].unique() |
drop_duplicates(针对dataframe去重也可series)====实质针对的是所有的列字段
1 | 全部字段 |
replace替换指定字符
1 | df.replace(np.nan,0,inplace=True) |
describe\info
1 | 查看汇总统计 |
数据合并merge\concat\join
1 | pd.merge(df1, df2, on='key', how='left') |
date_range 创建时间数据
1 |
|
value_counts数据频数统计
1 | 对某一行或者某一列数据进行频数统计 |
数据统计
1 | df.describe():查看数据值列的汇总统计 |
数据选取(isin和str.contains)
isin(df和series都可用)
1 | 判断是否含所有某个数据(完全匹配)等于多个数值或者字符串时 内容为列表格式--符合任意一个都会返回 |
str.contains(针对的为series)
1 | 判断某个数据中是否包含指定字符(字符串的模糊筛选) |
set_index 和 reset_index
1 | 将df1中A这一列设为索引,并且不删除原来的A那一列 |
rank
1 | df.rank() #默认按照列排序,返回的结果为对应各自排名的矩阵 |
1 | sorted(cxy_data, key=lambda i: i['num'], reverse=True) 按照字典中的某个值倒叙 |
#####to_excel1
2
3writer = pd.ExcelWriter(r'C:\Users\Administrator\Desktop\ceshe.xlsx')
data.to_excel(writer,sheet_name='Sheet1')
writer.save() #直接将df导出到excel中
#####stack和unstack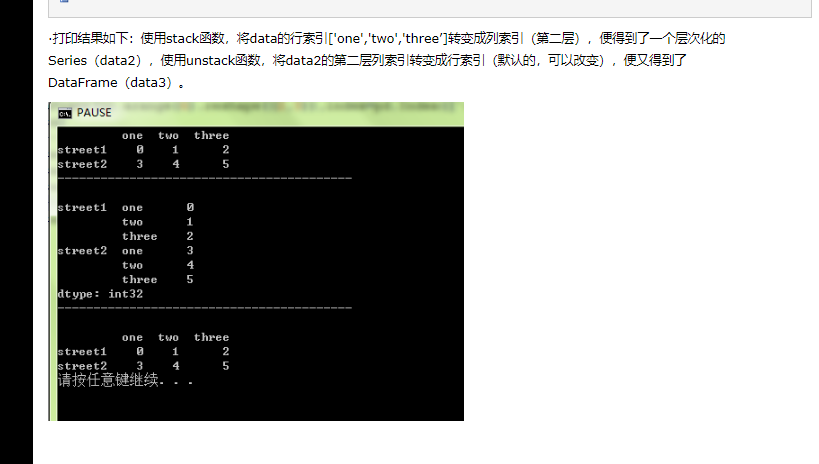
pandas分行取top多少
1 |
|
Python操作excel方法 对比
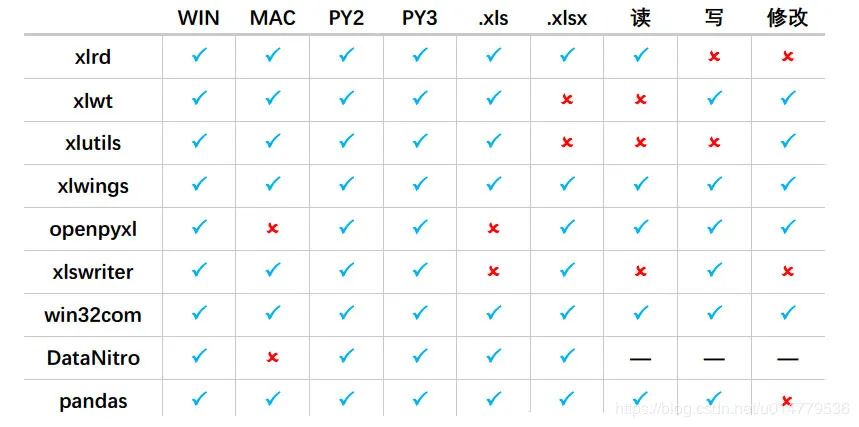
优化方法
1 | df.eval( |
等长列表两两元素操作
1 | list(map(lambda x :x[0]+x[1] ,zip(a,b))) |
传参
1 | outer_params = [company_table,zl_zu_table,replace_rate_group_table,techonology_life_replace_table,zhibiao] |
dataframe插入clickhouse
1 | client = Client(host='192.168.0.170', port='9000', user='algorithm', password='1a2s3d4f', database='algorithm_dis',settings={'use_numpy': True}) |
transform
1 | 超级好用,支持在原有基础上新增一列,支持groupby后的操作 |
shift
1 | 整体向下平移,支持groupby后shift,搭配assigh使用 |
python离线安装第三方whl文件
1 | pip download pandas -d E:\光大POC\fin_indicators |
其他
1 | pip freeze > requirments.txt |
从windows到linux部署

内存回收
1 | 数据使用的进程不销毁,占用的内存不会减少,因而可以通过创建子进程实现回收 |
转换数类型神器
df.convert_dtypes
补充:其他的常用方