推荐网址:https://blog.csdn.net/weixin_41624982/article/details/89486592
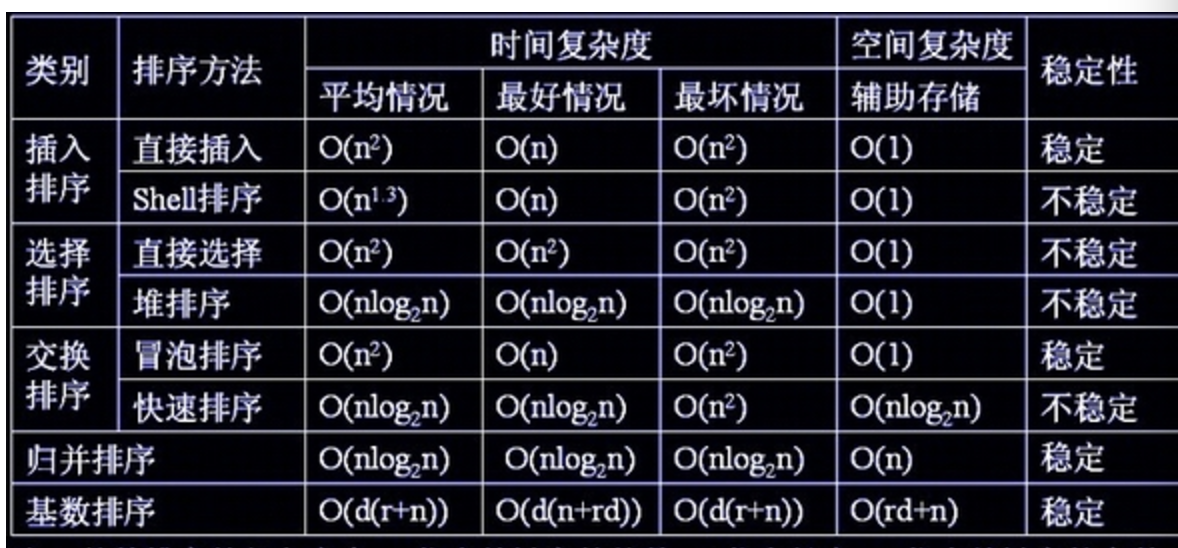
基本概念
1 | 1.描述:抽象数据类型(ADT),是计算机领域中被广泛接受的一种思想和方法,也是一种设计和实现程序模块的有效技术.模块通过接口来提供功能所需的信息,并不涉及具体实现细节. |
几种树
1 | 满二叉树:除了叶子结点,每一个节点都有两个子节点(深度k 节点总数为(2^k)-1,则它就是满二叉树) |
####python实现链表
输入一个链表,按链表从尾到头的顺序返回一个ArrayList(牛客网)==形如栈
1 | # -*- coding:utf-8 -*- |
二分法(仅当列表是有序的时候有用)=====第一种算法
1 | 简单查找(傻找):如1到100中找99,一个个找需要99次. |
大O表示法(记录的是最糟糕最长的时间情况)
1 | 用来表示算法的运行时间,以及运行时间随着列表的增长的变化情况:如对数越往后几乎不增长,而线性一直增长很快 |
####数组和链表
1 | 数组表明所有代办事项在计算机的内存中是相连的,紧靠在一起,当后面位置被占用的时候,就需要整体迁移到有空闲位置的地方(他们必须相连),添加元素速度很慢 |
链表在插入数据上面的优势特别明显(无论结尾插入还是中间插入),数组在随机读取速度的优势特别明显,链表删除数据也比较方便。不同如插入,删除操作一定能成功,插入操作当内存空间不够时,插入操作可能会失败。删除操作任何情况都能成功
1 | 链表读取时间O(n),存储时间O(1),删除时间O(1) |
1 | 为什么数组都是以0为开头的索引? |
选择排序=====第二种算法
1 | 如一堆数中按照大小进行排序,每次的时间复杂读为O(n),执行n次,总的为O(n**2) |
python实现选择排序
1 | def func(ls,data_max): |
快速排序(D&C算法)=====第三种算法(基础:递归)
1 | 快排比选择排序快很多,是一个优雅的算法(并非一种解决问题的算法,而是一种解决问题的思路) |

####合并排序(归并排序)
1 | 合并排序的时间总是O(nlogn),而快排平均时间为O(nlogn),最糟糕时候为n**2 |

插入排序
1 | 基本思想:把待排序的记录按照其关键码值的大小逐个插入到一个已经排好序的有序序列中,知道所有的记录插完为止,得到一个新的有序序列 |
散列表
1 | 散列表也称为散列映射、映射、字典和关联数组。 |
广度优先搜索(通过队列实现,顺序添加,顺序查找)
1 | 广度优先搜索是用来解决最短路径问题的,是一种用于图的查找算法,主要解决两类问题 |
狄克斯特拉算法
1 | 加权图:带权重的图 |
第一步:找出最便宜的节点.使用散列表,把它当成一个列表
| 父节点 | 节点 | 耗时 |
|---|---|---|
| 起点 | A | 6 |
| 起点 | B | 2 |
| 起点 | 终点 | 未知 |
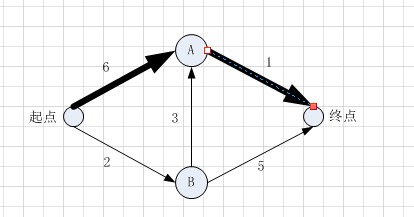
找出最短耗时2,节点B是最近的
第二步:计算经节点B前往其各个邻居所需的时间
| 父节点 | 节点 | 耗时 |
|---|---|---|
| B | A | 5(2+3) |
| B | B | 2 |
| B | 终点 | 7(2+5) |
第三步:重复操作
贪婪算法(贪心算法)===局部最优解,企图以这种方式获得全局最优解
1 | 指的是,在对问题求解时,总是做出当前看来最好的选择,也就是说,不从整体最优上加以考虑,做出的是某种意义的局部最优解 |
动态规划(DP=dynamic programming)
1 | 这是一种解决棘手问题的方法,将问题分解成若干个小问题,先着手解决这些小问题 |
树算法
1 | 树:树是一种管理有像树干、树枝、树叶一样关系的数据得数据结构 |
图地址:https://img2018.cnblogs.com/blog/1244002/201809/1244002-20180921160023094-1488648937.png
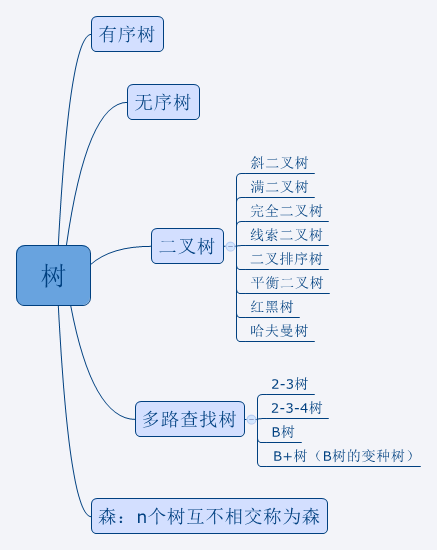
各种树介绍
1 | #有序树与无序树 |
堆
1 | 堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针,堆根据堆属性来排序,堆属性决定了树中节点的位置 |