##基础知识
文章来源:https://www.jianshu.com/p/47664afa249e
Mysql的常用引擎
1 | 1.Innodb(更适合高并发场景) |
Mysql的数据、索引存储结构
1 | 1.数据存储的原理(硬盘) |
Mysql中的B+Tree
1 | 目前大多数的数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构 |
####B-Tree
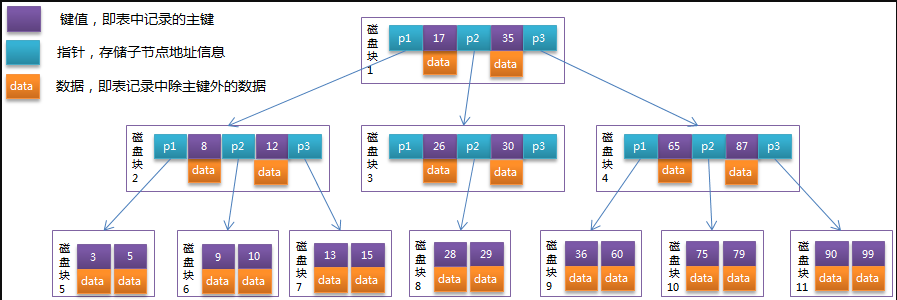
查找关键字29的过程:
1.根据根节点找到磁盘1,读入内存(磁盘i/o操作一次)
2.根据关键字29在区间(17,35),找到磁盘块1的指针p2
3.根据p2指针找到磁盘块3,读入内存,磁盘i/o操作第二次
4.比较关键字29在区间(26,30),找到磁盘块3的指针p2
5.根据p2指针找到磁盘块8,读入内存,磁盘i/o操作第三次
6.在磁盘块8的关键字列表中找到关键字29
Mysql的Innodb存储引擎在设计时是将根节点常驻内存的,因此力求达到树的深度不超过3,也就是I/O不需要超过3次
根据上面的过程可以发现需要3次磁盘I/O操作,和3次内存查找工作.由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率,因而3次磁盘的I/O操作是影响整个B-tree查找效率的决定性因素
B-Tree 相对于平衡二叉树缩减了节点个数,使每次I/O取到内存的数据都发挥了作用,从而提高了查询效率
B+Tree是在B-Tree的基础上的一种优化,使其更适合实现外存储索引结构,Innodb存储引擎就是用B+Tree实现其索引结构
在B-Tree中,每个节点中有key,也有data,而每一个页的存储空间有限,如果data数据较大时会导致每个节点(即一个页)能存储的的key数量很小
在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子结点上,
而非叶子结点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度
B+Tree和B-Tree的区别
1.数据是存在叶子节点上中的
2.数据节点间是有指针指向的
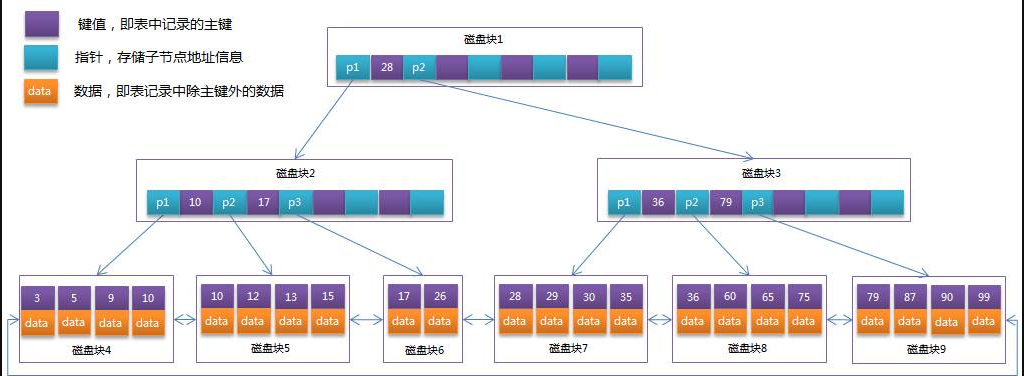
Myisam中的B+Tree
Myisam引擎也是采用的B+Tree结构作为索引结构
由于Myisam中的索引和数据存放在不同的文件,所以在索引树中的叶子结点中存的数据是该索引对应的数据记录的地址,由于数据和索引不在一起,所以Myisam是非聚簇索引
(叶子结点存放对应数据的物理地址)
#####Innoodb中的B+Tree
Innodb是以ID为索引的数据存储
采用Innodb引擎的数据存储文件有两个,一个定义文件,一个数据文件
Innodb通过B+Tree结构对ID建索引,然后通过叶子结点中存储记录
若建索引的字段不是主键ID,则对该字段建索引,然后在叶子节点中存存的是该记录的主键,然后通过主键索引找到对应记录
#####Mysql的相关优化
1.Mysql性能优化:组成,表的设计
①开启查询缓存.避免某些sql函数直接在sql语句中使用,从而导致Mysql缓存失效
②目的是什么就取什么,能查一条判断的就不要全取
③建合适的索引,所以要建在合适的地方,合适的对象上,经常操作/比较/判断的字段应该建索引
④字段大小要适宜.字段的取值是有限而且固定的,这种情况下可以使用enum,ip字段介意用unsigned int来存储
⑤表的设计.垂直分割表,使得固定表与边长表分割,从而降低表的复杂度和字段的数目
2.SQL语句优化:避免全表扫描
1.建索引 一般在where及order by中涉及到的列上建索引,尽量不要对可以重复的字段建索引.
2.尽量避免在where中使用!或or也不要进行null值判断
3.尽量避免在where中对字段进行函数操作、表达式操作
4.尽量避免使用llike %,在这种情况下可以进行全文检索
Mysql基准测试
原因:基准测试可以观察系统在不同压力下的行为,评估系统的容量,掌握哪些是重要的变化,或者观察系统如何处理不同的数据
######基准测试的策略:
针对整个系统的测试(集成式full-stack)
单独测试Mysql(单组件式single-component)
测试的指标
1.吞吐量,指单位时间内的事务处理数,常用的测试单位是每秒事务级(TPS),或每分钟事务数(TPM)
2.响应时间或者延迟,用于测试任务所需的整体时间,根据具体的应用,测试的时间单位可能是微秒毫秒秒或者分钟.通常使用百分比响应时间来代替最大响应时间
3.并发性,需要关注的是正在工作中的并发操作,或者是同时工作中的线程数或者连接数.在测试期间记录Mysql数据库的Threads_running状态值
4.可扩展性,给系统增加一倍的工作,在理想状态下就能获得两倍的效果(即吞吐量增加一倍),对于容量规范非常有用,可以提供其他测试无法提供的信息
基准测试方法
1.需要避免的一些常见错误:
使用真实数据的子集而不是全集
使用错误的数据分布
使用不真实的分布参数
在多用户的场景中,只做单用户测试
在单服务器上测试分布式应用
与真实用户行为不匹配
反复执行同一个查询
没有检查错误
忽略了系统预热(warm up)过程
使用默认的服务器配置
测试时间太短
2,应该建立将参数和结果文档化的规范,每一轮测试都必须进行详细记录
3.基准测试应该运行足够长的时间,需要在稳定状态下测试并观察
4.在执行基准测试时.需要尽可能多地收集被测试系统的信息
5.自动化基准测试可以防止测试人员偶尔遗漏某些步骤,或者误操作,宁外也有助于归档整个测试过程
剖析mysql查询
1 | 1.剖析服务器负载 |
诊断间歇性问题
1 | 1.尽量不要用试错的方式来解决问题,如果一时无法定位,可能是测量的方式不准确,或者测量的点选择有误,或者使用的工具不合适 |
Schema与数据类型优化
1 | schema就是数据库对象的集合,所谓的数据库对象也就是常说的表,索引,视图,存储过程等。 |
加快alter table操作的速度
1 | 1.在一台不提供服务的机器上执行alter table操作,然后和提供服务的主库进行切换 |
快速创建Myisam索引,先禁用索引,导入数据,然后重新启用索引
创建高性能的索引
1 | 一.索引基础 |
五.查询性能优化
1 | 1.为什么查询速度会变慢 |
查询优化器
1 | 一.Mysql查询优化器的局限性 |
######Mysql高级特性
1 | 一.分区表 |
优化服务器设置
1 | 一.mysql配置的工作原理 |