第一讲 Mysql查询执行流程(笔记来自极客时间)
1.mysql架构
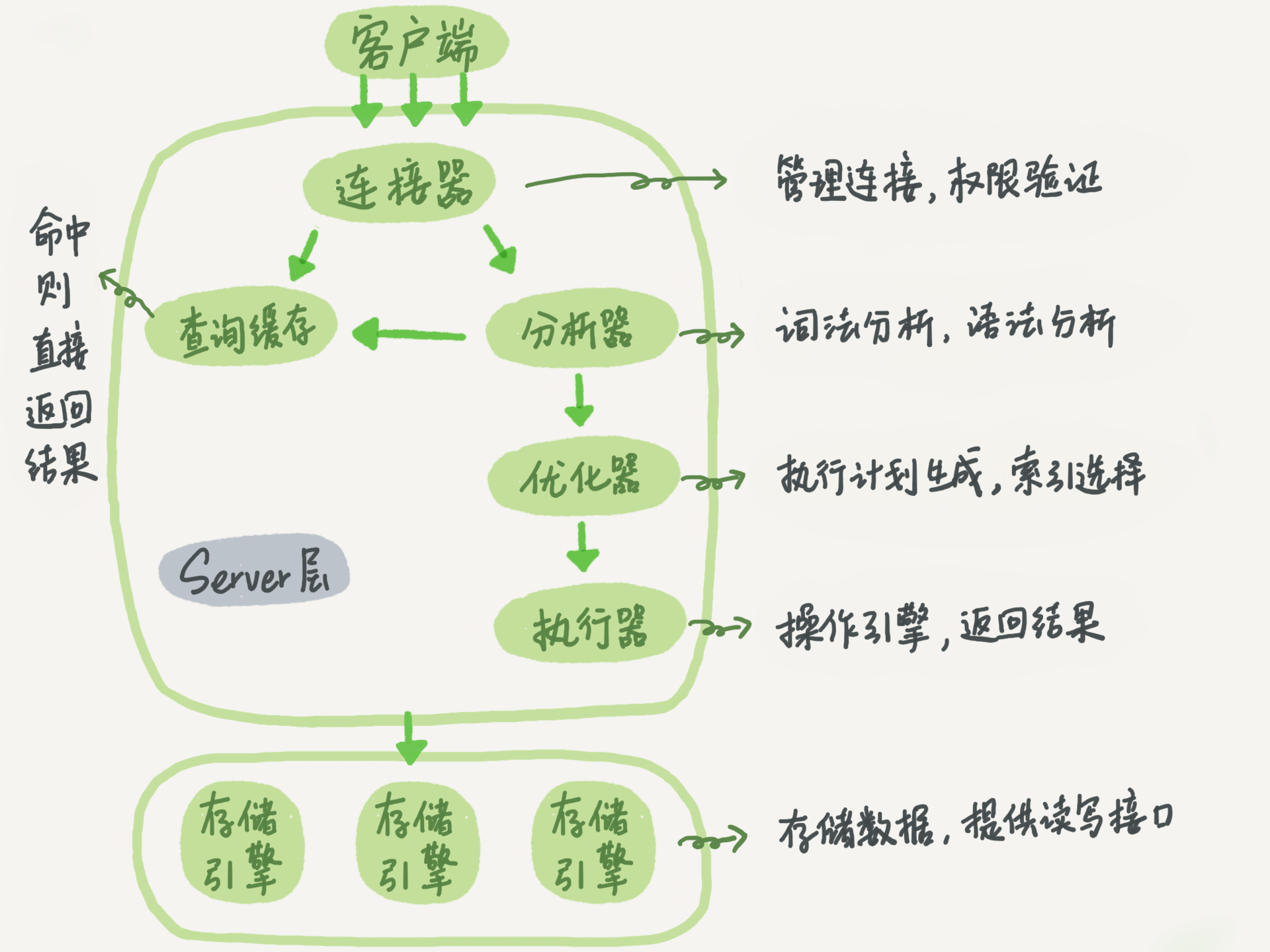
2.架构解释
①mysql架构由两部分组成,server端和存储引擎
② 连接器:建立连接,验证权限,维持和管理连接
分析器:首先分析每个词代表的含义,然后分析整个sql语句的语法
查询缓存:键值对形式,sql语句对应数据缓存,命中sql,则直接返回数据。
优化器:join时优先表的选择,及多索引优先索引选择
执行器:表权限验证,操作引擎获取数据
③ 其他补充:
1)查询缓存在8.0版本取消,查询缓存并没有想象中那么好用,命中率很低,而且表变化后缓存就会清空,适合静态表,很久才更新的那种
2)如果查询缓存命中的时候,会在返回数据的时候做权限验证,验证是否有这张表的权限
3)执行器,在执行sql前先判断是否对表有执行查询的权限,有则从引擎取数据
第二讲 Mysql更新记录操作流程
总体:1.查询的执行过程同查询过程一致
2.一个表的数据更新的时候,跟这个表相关的所有缓存都会消失
3.不同于查询,更新涉及到两个日志模块。redo log和binlog
redo log:(保证数据不会丢失)—->innodb特有
1.目的:每次更新都需要写到磁盘,然后磁盘也要找到那条记录然后更新数据,这样导致整个IO成本和查找成本都很高.同时redo log
2.日志和磁盘和结合,即所说的WAL技术(write ahead logging),即先写日志,再写磁盘(不忙的时候),日志写满则开始写入磁盘
补充:日志存储在磁盘里,写日志用的是顺序IO,更新操作用的是随机IO,而顺序IO比随机IO 快很多(随机IO要寻址)
3.crash safe能力:数据库异常重启时,不会丢失数据
binlog:(server层特有)—->所有引擎共用
1.没有crash_safe能力
2.为什么会有两个日志?因为本来mysql 并没有innodb引擎,所以只有binlog日志,后来innodb作为插件引入到mysql,由于binlog没有crash-safe能力,所以引入了新的日志系统redo-log.binlog用于归档
redolog和binlog的区别
1.redo是innodb引擎特有的,而binlog是所有引擎共有的
2.redo是物理日志,记录在某个<数据页>做了什么修改,binlog是逻辑日志.记录了sql
Binlog有两种模式,statement 格式的话是记sql语句, row格式(常用)会记录行的内容,记两条,更新前和更新后都有。
3.redo log是循环写,空间有限制,写完了就写入磁盘然后重新写.而binlog是追加写,一个文件达到一定大小后,开始下一个
update流程
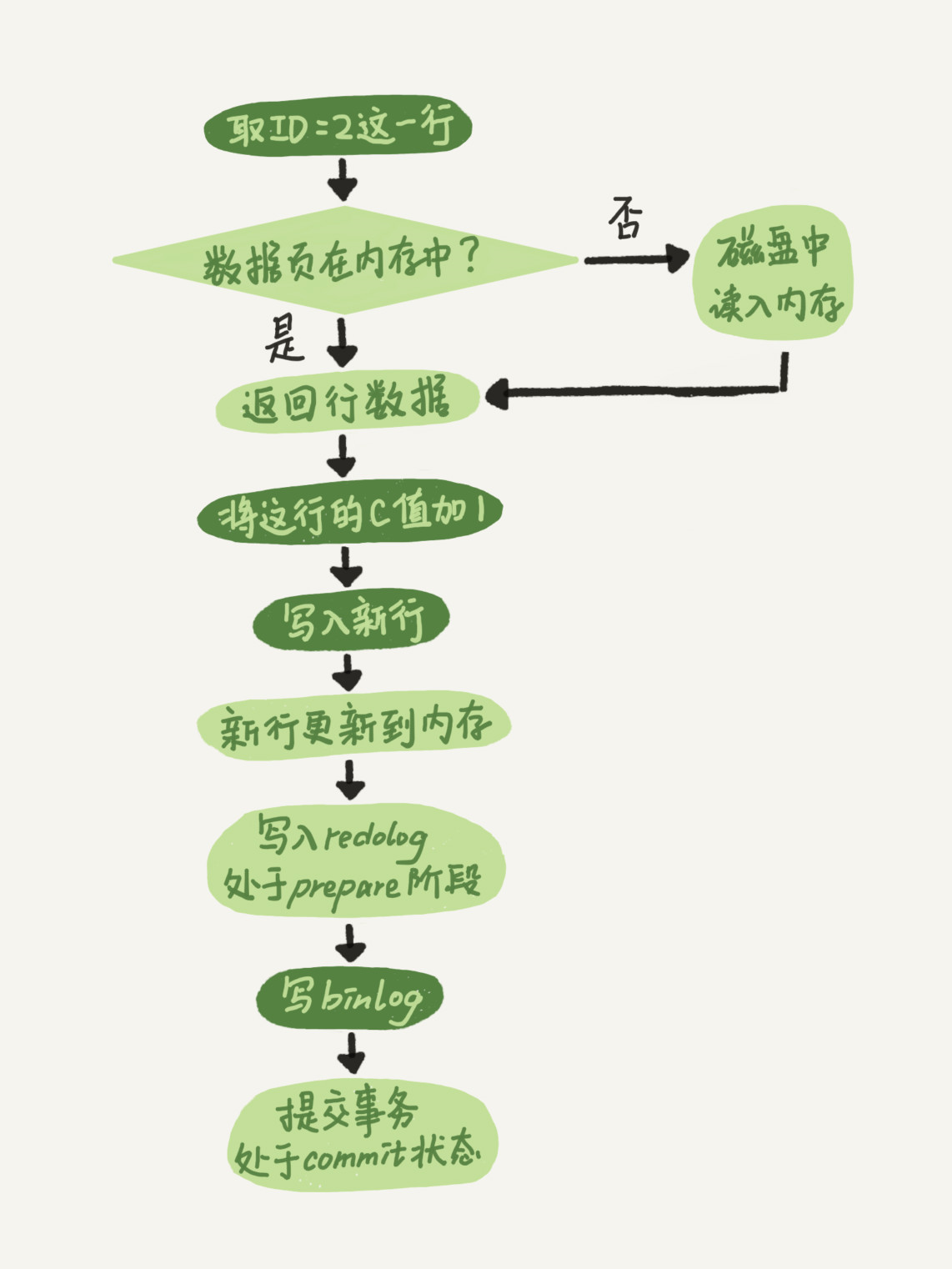
1.获取id=2这行判断是否在缓存里.若果是则直接获取,不是则从磁盘读取.
2.将这行数据的c+1
3.写入新行
4.引擎将这行数据更新到内存中,同时记录在redo log中,次数redo log处于prepare阶段,随时可提交事务
5.执行器生成这个操作的binlog,并将binlog写入磁盘
6.执行器调用引擎执行事务的接口,redo log处于commit阶段—>两阶段提交为了让binlog和redo log的逻辑一致
binlog数据恢复过程
1.假如无删除操作,恢复数据需要最近一次的全量备份数据和现在的binlog,但是需要将binlog里无删除操作去掉,然后将binlog放到旧数据的指定位置.这样就恢复了
为什么要分两段提交以及提交的顺序(这里不使用分段提交)
1.先写redo log 后写bin log
假设redo log 写完后,系统重启,这时候binlog还没写,redo log 写过,这样当使用binlog恢复数据时,就会出现数据库少了一次更新
2.先写bin log 后写 redo log
假设在写完binlog时候crash,由于redo log没有提交,则重启后事务无效,但是binlog已经更改,这样,当恢复数据的时候就会出现多了一次事务
第三讲 事务隔离
事务:保证对数据库操作的一致性,一组操作全部成功或者全部失败
1.Innodb支持事务而Mysiam不支持
2.事务的隔离性和隔离级别
①事务的特性:ACID,原子性,一致性,隔离性,持久性
②多事务可能出现的问题:脏读,幻读,不可重复读
脏读:读到其他事务未提交的数据
幻读:前后读取的记录数量不一致
不可重复读:读取前后的数据不一致
③事务的隔离级别(为了解决上面的多事务问题):读未提交,读已提交,可重复读,序列化(串行化)
读未提交(RU):一个事务没提交,但是变更可被其他事务看到
读已提交(RC):一个事务提交后,变更才能被其他事务看到
可重复读(RR):事务在执行过程中读到的数据和事务启动时的数据一致
串行化(Serial):指的是会给同一行加锁.读锁和写锁.当读写冲突时,后面的事务需要等前一个事务结束后才行
$\textcolor{red}{总结:}$
1.在实现上,主要是通过MVCC视图(数据库会创建),但是针对RU是没有是没有视图概念的,直接返回记录上的最新值
2.针对RC,是在每一个SQL语句开始执行的时候创建的视图
3.RR是在事务启动时候创建的视图
4.Serial直接用加锁的方式避免并行,无视图概念
$视图的概念:$视图是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。是基于 SQL 语句的结果集的可视化的表,可以包含表的全部或者部分记录,也可以由一个表或者多个表来创建.实际上是在数据库里执行了SELECT语句,SELECT语句包含了字段名称、函数、运算符,来给用户$\textcolor{red}{显示数据}$。
2.事务隔离的实现
在数据更新的时候mysql的redo log会做一个变更记录,同时与变更相反的回滚操作记录会记录在undo log上
例:回滚日志记录
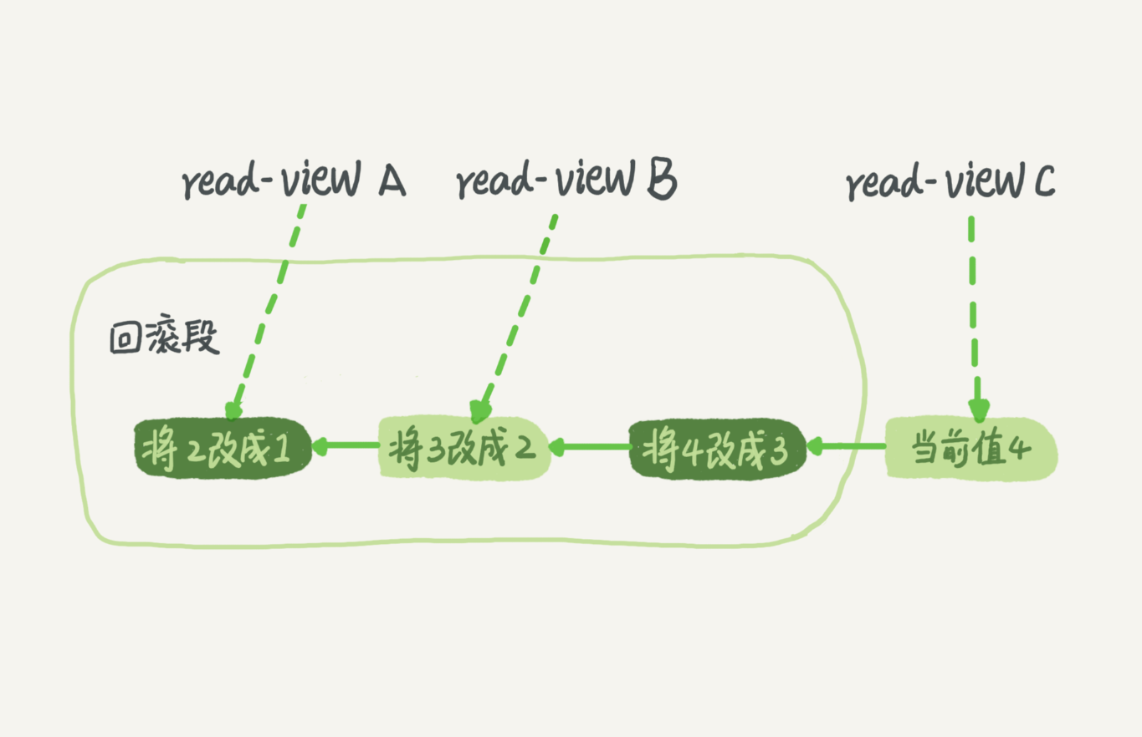
原操作是从1到2再到3再到4.当前值为4,但是不同时刻启动的事务会有不同的视图.同一条记录在系统中可以存在多个版本,这就是数据库的多版本并发控制(mvcc).
回滚日志并非一直并非一直存在,当系统中没有比日志更早的视图的时候,回滚日志就会被删除
所以尽量避免长事务.长事务导致undo log一直存在不会被删除.且会占用大量的空间
第四讲深入浅出索引(一种数据结构)
1.常见的索引模型
1 | 1.哈希表:一种以键值存储数据的结构,原理是当传入一个键的时候,会通过哈希函数返回一个位置,直接将位置的value取出即可.但是存在不同的键经过哈希函数以后返回相同的value.处理这种情况是拉开一个链表。 |
$\textcolor{red}{总结:}$数据库的底层核心就是这些数据模型,碰到一个新的数据库需要关心它的数据类型,这样才能在理论上分析数据库的适用场景
2.Innodb的索引模型
在 InnoDB 中,每一张表其实就是多个 B+ 树,即一个主键索引树和多个非主键索引树
$\textcolor{red}{使用B+树的原因}$B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
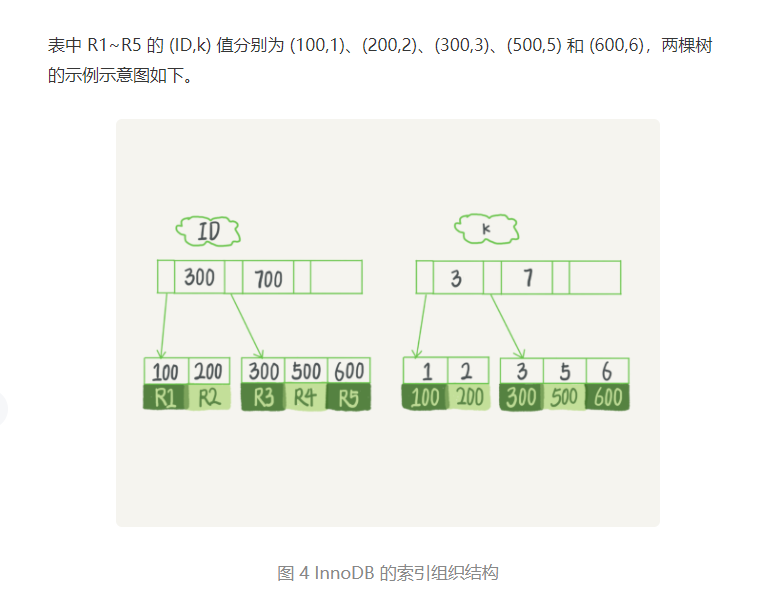
主键索引: key:主键的值,value:整行数据。 普通列索引: key:索引列的值, value:主键的值。
$\textcolor{red}{回表}$
1 | ID为主键索引,k为普通索引 |
3.索引维护
1 | B+Tree为了维护索引的有序性,在插入新值的时候需要做必要的维护.(上图,比如数据现id为700,添加新的行的id为700,则只需要在r5后面记录插入的新纪录,如果插入的值为400,则需要挪动后面的数据,空出位置.假如R5的数据页已经满了,则需要在申请一个新的数据页,然后挪动数据过去--->页分裂.--->影响数据页的利用率,原本一个页的数据放到了) |
第六讲:全局锁和表锁
1 | 锁涉及的初衷:处理并发问题 |
全局锁
1 | 说明:给整个数据库实例加锁 |
表级锁
1 | 分类:表锁,元数据锁(MDL) |
行级锁
1 | 行锁是各个引擎自己实现的,并不是所有的引擎都支持行锁,不支持的只能使用表锁 |
linux 装mysql5.7
1 |
|
1 |