Apache重要的三个基金会项目(hadoop,spark,storm)
Spark提供了内存计算,减少了迭代计算时的IO开销;虽然,Hadoop已成为大数据的事实标准,但其MapReduce分布式计算模型仍存在诸多缺陷,而Spark不仅具备Hadoop MapReduce所具有的优点,且解决了Hadoop MapReduce的缺陷。
Spark:可以作为一个更加快速、高效的大数据计算平台。基于内存的大数据并行计算框架.将计算分解成多个任务在不同的机器上运行.
别人的学习总结:https://blog.csdn.net/qq_33247435/article/details/83653584#8Spark_71
spark的概念
1.$RDD$(resilient distribute dataset 弹性分布式训练集).是分布式内存里的一个抽象概念,表示的是高度受限的共享内存模型
2.$DAG$(directed acyclic gragh),有向无环图,表明了RDD之间的依赖关系
3.$EXECUTOR:$运行在工作节点上的一个进程,负责运行任务,以及应用程序存储数据
4.$程序:$编写的spark程序
5.$任务:$运行在executor上的工作单元
6.$作业:$包含多个RDD及对应RDD上的操作
7.$阶段:$作业的基本调度单位,一个作业会分成多组任务,每组任务称为阶段
8.$shuffle过程:$简单认为就是将不同节点上的相同key拉到同一个节点上计算
9.$SparkSession:$代表了spark集群中的一个连接,在应用程序实例化的时候启动
====>spark的入口,2.0之前spark core是sparkcontext,spark sql是sqlcontext,sparkstreaming应用使用streamingContext.2.0之后,sparksession对象把所有的对象组合到一起.称为所有程序统一的入口
RDD详解(待补充)
pass
spark运行架构
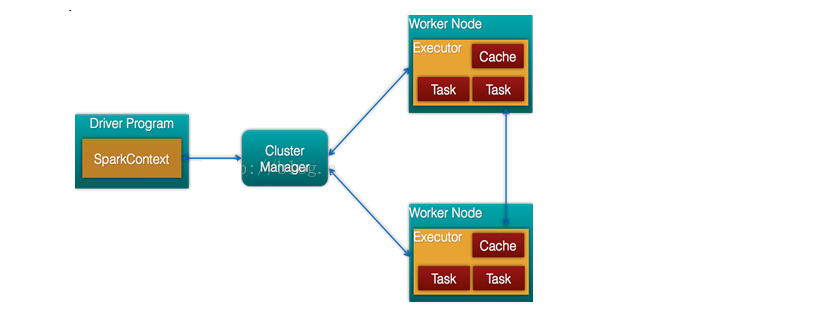
$driver:$每个应用的任务控制节点
$cluster manager:$集群资源管理器
$node:$运行作业任务的工作节点
$Executor$:每个工作节点上负责具体任务的执行进程
$\textcolor{red}{关系:}$
一个应用由一个一个控制节点(driver)和若干个作业构成,一个作业由若干个阶段构成,一个阶段由多个任务构成.当执行一个应用时,任务控制节点会向集群管理器申请资源,启动executor,并向executor发送应用程序和代码和文件.然后在executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到数据库中.
$\textcolor{red}{Executor优点:}$
1.采用的是多线程(map reduce 使用的是进程模型),减少了开销
2.executor中有一个blockmanager存储模块,会将内存和磁盘作为存储模块,当需要多轮迭代计算的时候,可以将数据存储到这个模块.有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
spark运行基本流程
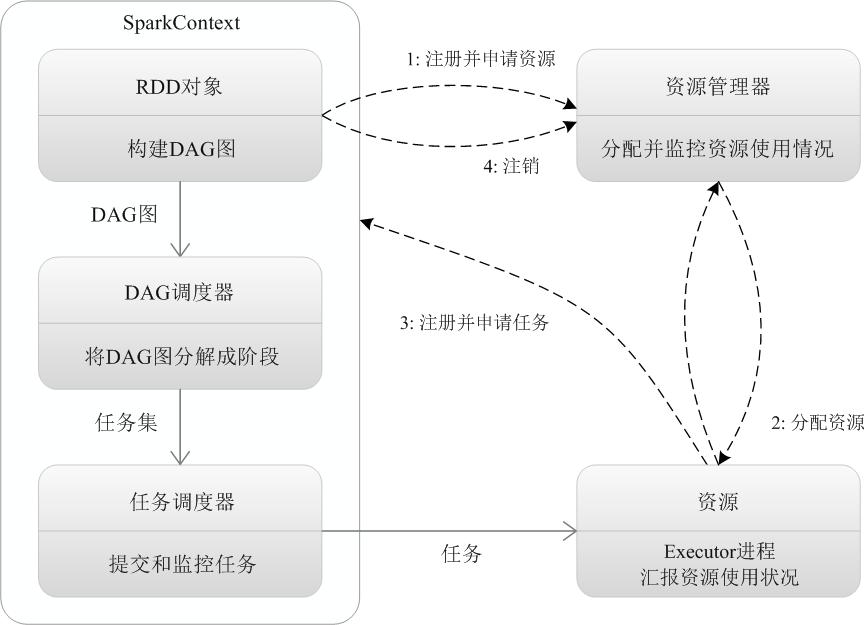
1.当一个spark应用被提交时,需要为这个应用提供基本的运行环境,即有任务控制节点(driver)创建一个sparkcontext,负责和资源管理器的通信以及资源的申请和任务的分配和监控等.sparkcontext会向资源管理器注册并申请运行Executor的资源.
2.资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着心跳发送到资源管理器上
3.任务在Executor上运行,并将结果返回给任务调度器,然后反馈给DAG调度器,运行完毕,写入资源并释放所有资源.
$\textcolor{orange}{详解}$
1.构建spark applicantion的运行环境,启动SparkContext
2.sparkcontext向资源管理器申请运行Executor
3.Executor向Sparkcontext申请Task
4.SparkContext将应用程序分发给Executor
5.sparkcontext构建DAG图,将DAG图分解成Stage,将tasket发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
6.Task在Executor上运行,运行完释放所有资源
$\textcolor{red}{SparkContext原理:}$
依据RDD的依赖关系构建DAG图,然后将DAG图提交给DAG调度器进行解析,将DAG图分解成多个阶段,并计算出各个阶段的依存关系,然后把一个个任务集提交给底层的调度器进行处理.Executor向sparkcontext申请人无,任务调度器将任务发送给Executor并将应用程序代码发送给Executor
spark on standalone流程
1 | 1、我们提交一个任务,任务就叫Application |
spark部署
$\textcolor{red}{三种部署方式:}$1.standalone 2.spark on Mesos 3.spark on YARN
$\textcolor{green}{standalone:}$
分布式集群服务,自带的完整服务,Spark自己进行资源管理和任务监控,一定程度上来说,此模式是其他两个模式的基础
$\textcolor{green}{Sapark on Mesos:}$
官方推荐(都是apache的),spark设计之初就考虑支持mesos,spark在mesos上比在YARN上更灵活
$Mesos$是一种资源调度管理框架
$两种调度模式:$
1.粗粒度模式
每个应用程序的运行环境由一个driver和若干个executor组成.其中,每个executor占用若干资源,内部可运行多个Task,应用程序在开始之前需要将运行环境的资源全部申请好,且运行过程中要一直占用这些资源,即使不用.当程序结束时,会进行回收.
2.细粒度模式
粗粒度会造成很大的资源浪费,动态分配
$\textcolor{red}{Spark on Yarn}$
是一种最有前景的部署模式。但限于YARN自身的发展,目前仅支持粗粒度模式
Spark可运行于YARN之上,与Hadoop进行统一部署
分布式部署集群,这是由于YARN(资源管理器)上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化.
spark相对hadoop的优势
hadoop的mapreduce计算模型延迟过高,无法胜任$\textcolor{red}{实时}$和$\textcolor{red}{快速}$计算,只适用离线批处理
$hadoop的缺点$:
1.表达能力有限.分为map阶段和reduce阶段.难以描述复杂数据处理过程.
2.磁盘io开销大.每次执行都需要从磁盘读取数据,且存的时候需要将中间数据存到磁盘中.
3.延迟高,一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接涉及到IO开销,会产生较高的延迟.
$Spark的优点$:
1.计算模式也属于MapReduce,但不局限于map和reduce操作,提供多种数据类型操作,比MapReduce更灵活
2.spark提供了内存计算,中间结果直接放到内存中
3.spark使用的是DAG进行任务调度,比MapReduce的迭代执行机制强
$整体:$
spark最大的优点就是将计算结果,中间数据存储到内存中,大大减少了IO开销.因为spark更适合迭代运算多的数据挖掘和机器学习运算
$总:$尽管整体上spark比hadoop要好,但是无法完全替代hadoop,通常是用来替代hadoop的MapReduce部分
spark生态
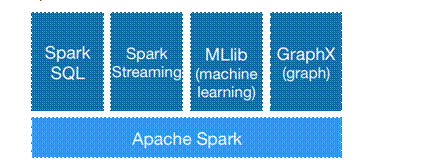
spark生态主要包含$\textcolor{red}{Spark Core}$ ,$\textcolor{red}{Spark Sql}$,$\textcolor{red}{Spark Screaming}$,$\textcolor{red}{MLlib}$,$\textcolor{red}{Graphx}$
$\textcolor{red}{Spark Core:}$Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。通常所说的Apache Spark,就是指Spark Core
$\textcolor{red}{Spark Sql:}$Spark SQL允许直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
$\textcolor{red}{Spark Screaming:}$ Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。
$\textcolor{red}{Graphx:}$GraphX是Spark中用于图计算的API
$\textcolor{red}{MLlib:}$MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等
在pyspark中执行词频统计
$案例1.词频统计$
①首先创建一个worldcount目录(shell 命令下)
②然后创建一个txt文件,里面随便写一些文字.作为统计的原材料
③词频统计需要启动pyspark.cd /usr/local/spark 然后 ./bin/pyspark
④加载文件—>确定是在本地还是在分布式的hdfs上
$本地$:
textFile = sc.textFile(‘file:///usr/local/spark/mycode/wordcount/word.txt’)(要加载本地文件,必须采用“file:///”开头的这种格式)–>惰性的,需要first()这种才能打印出数据
textFile.first()(打印第一行数据,文件不存在会显示拒绝连接)
$HDFS$:
需要首先启动Hadoop中的HDFS组件
1. cd /usr/local/hadoop
2. ./sbin/start-dfs.sh
$\textcolor{red}{上传文件到hdfs上}$./bin/hdfs dfs -put /usr/local/spark/mycode/wordcount/word.txt .
3.加载文件textFile = sc.textFile(“hdfs://localhost:9000/user/hadoop/word.txt”)–>惰性的
⑤写代码,在pyspark窗口(类似于ipython那种>>>),代码如下
textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”)
wordCount = textFile.flatMap(lambda line: line.split(“ “)).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)
wordCount.collect()
$\textcolor{red}{代码解释:}$
1.第一行即从本地加载文件数据
2.第二行textFile.flatMap(lambda line: line.split(“ “))表示按行处理,每行按照空白符分割.这样每行得到一个单词集合.textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合.map(lambda word: (word,1))会遍历单词集合中的每一个单词,并执行Lamda表达式word : (word, 1).
程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey(labmda a, b : a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:a, b : a + b)
如:(“hadoop”,1)和(“hadoop”,1)—–>(“hadoop”,2)
编写独立应用程序执行词频统计
1.创建test.py文件内容如下
from pyspark import SparkContext
sc = SparkContext( ‘local’, ‘test’)
textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”)
wordCount = textFile.flatMap(lambda line: line.split(“ “)).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)
wordCount.foreach(print)
在集群上运行spark
1 | 1.启动hadoop集群 |
$\textcolor{red}{spark-submit}$ 可以提交任务到 spark 集群执行,也可以提交到 hadoop 的 yarn 集群执行。
bin/spark-submit –class org.apache.spark.examples.SparkPi –master表示以集群模式启动spark
Jupyter Notebook调试PySpark
RDD的弹性
1 | 1.自动的进行内存和磁盘的存储切换 |
主从架构 和 P2P架构
宽依赖 债依赖
shuffle操作
fork和join
RDD运行原理
1 | 1.RDD无法直接更改数据,每次操作都会生成一个新的RDD |
RDD可以实现高效计算的原因
1 | 1.高效的容错性。可以直接利用 RDD 之间的依赖关系来重新计算得到丢失的分区。 |
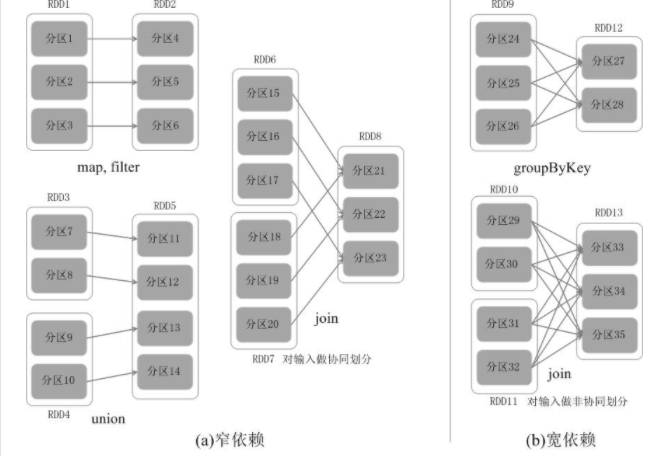
RDD之间的依赖关系
1 | 宽依赖:父 RDD 与子 RDD 之间的一对多关系,即一个父 RDD 转换成多个子 RDD |
RDD编程
######1.通过加载数据创建RDD
1 | from pyspark import SparkContext |
2.通过并行集合(数组)创建RDD
1 | 调用sparkcontext的parallelize方法,在Driver中一个已存在的集合(数组)上创建 |
RDD操作
1 | 1.转换:基于现有的数据集创建一个新的数据集 |
1.转换操作
1 | 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用。转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。 |
2.行动操作
1 | 行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。 |
######3.惰性机制解释
1 | lines = sc.textFile("data.txt") |
4.持久化
1 | 由于RDD采用的是惰性求值的方法,每次遇到行动操作都会从头开始计算,当程序有多个行动时,这样的代价就会很大. |
$rdd.foreach(print)或者rdd.map(print)打印输出$
$rdd.collect().foreach(print):将所有节点的数据打印,容易爆内存$
$rdd.take(100).foreach(print):打印RDD部分数据$
5,键值对RDD
1 | #首先创建键值对RDD---两种方法 |
#####共享变量
1 | 目的:要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量 |
1.广播变量
1 | 通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。 |
2.累加器
1 | 通常可以被用来实现计数器(counter)和求和(sum) |
RDD打印数据
1 | 1.rdd.foreach(print) |
#####
RDD运行原理—-阶段的划分和RDD的运行过程
1 | 宽依赖窄依赖 |
fork and join机制
####standalone环境配置
1 | Spark standalone部署配置 |
问题
1 | 1.Spark在计算的过程中,是不是特别消耗内存? |
运行spark程序
1 | sc.master可以查看当前的运行模式 |
pandas的DF和spark的DF对比
1 | 两者的异同: |
1 | 有效专利:针对一件专利,从申请日期开始,一直到失效日期都是有效的,若专利没有失效日期,需要结合当前状态去判断,如果当前状态为授权状态/再审状态,按照最大年限去认定失效日期,发明为20年,新型为10年.如果当前状态为失效,则判断不了具体失效时间,不做统计(总共只有一条). |
spark sql架构
1 | 1.列式存储 |
jupyter notebook连接spark
1 | import os |