1.介绍
1 | 1.Xgboost本质上还是GBDT(梯度提升树),Xgboost算法是对GBDT算法的改进 |
机器学习常用名词解释
正则化: 向你的模型加入某些规则,加入先验,缩小解空间,减小求出错误解的可能性,有效防止过拟合
超参数: 是人为设置值的参数,而不是通过训练得到的参数数据,如学习率
稀疏数据: 数据框中绝大多数数值缺失或者为零的数据,类推稀疏矩阵
离散数据(变量):指其数值只能用自然数或整数单位计算.例如,企业个数,职工人数,设备台数等,只能按计量单位数计数
连续数据(变量):指在一定区间内可以任意取值,相邻的两个数值可作无限分割(即可取无限个值)。比如身高,身高可以是183,也可以是183.1,也可以是183.111……1
离散特征:其数值只能用自然数来表示,只能用计量单位统计,如个数,人数等
连续特征:是按测量或者计量方法得到。连续特征是指在一段长度内可以任意获得的特征,其数值是不间断。比如[0,1]之间的数,可以取n个数。
总之,记住,离散只能用自然数表示,是统计得到的。连续是按测量或者计量到得到数,比如各种传感器采集得到的数。
核外计算: (内存外计算),大数据的数据规模下,一次性把训练数据导到内存里面计算是不实际的
1 | 三个计算级别:(速度越来越慢,数据量越来越大) |
分布式 spark,Hadoop方面
其他:待补充
Cart分类树和回归树实现原理
1 | 决策树三种方式:ID3(信息增益) C4.5(信息增益率) Cart(基尼指数) |
2.Xgboost的优点
1 | 1.正则化项防止过拟合 |
正则化
内容:包含L1正则化、L2正则化
以线性回归为例
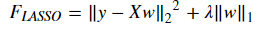 L1正则化
L1正则化
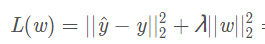 L2正则化
L2正则化
L1正则化最大的特点是能生成稀疏矩阵(主要用于特征选择,0和非0)
L2正则能够有效的防止模型过拟合
作用:解决过拟合,降低模型复杂度,防止参数过大(限制模型的参数)
正则化能实现过拟合原因:
1.作为惩罚项,惩罚特征权重w,当λ越大w越小,权重影响越小
2.直观的理解,如果我们的正则化系数λ无穷大,则权重w就会趋近于0。权重变小,非线性程度自然就降低了
##
3.Xgboost与GBDT的区别
1 | GBDT:梯度提升算法利用损失函数的负梯度作为残差拟合的方式,如果其中的基函数采用决策树的话,就得到了梯度提升决策树 |
拟合残差:最后结果相加就是预测的
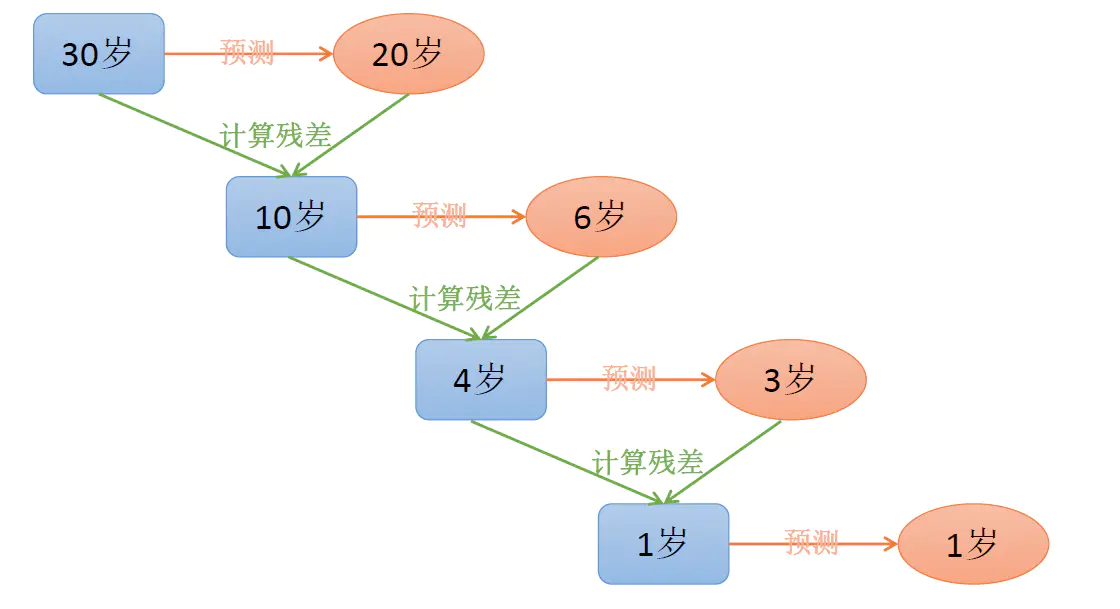
4.算法的实现过程
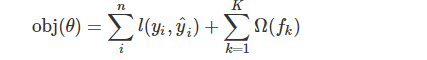
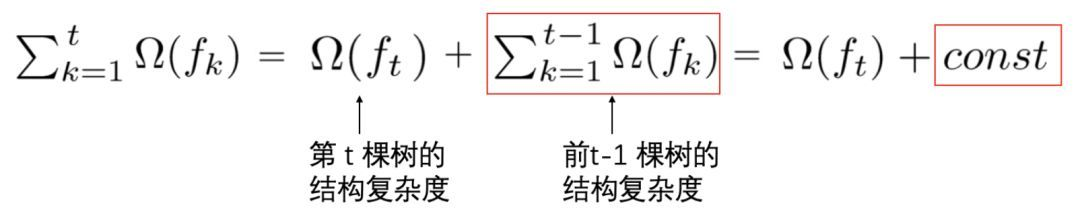
分别代表训练损失和树的复杂度
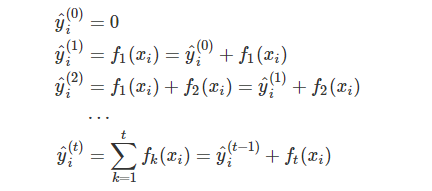

前t-1颗树的结构已经确定,认定为常数
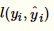 表示损失函数,如平方损失
表示损失函数,如平方损失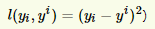
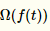 表示正则化项,考虑树的复杂度,防止过拟合
表示正则化项,考虑树的复杂度,防止过拟合
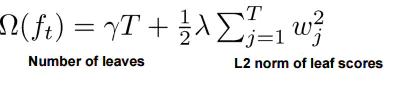
 表示常数项
表示常数项
损失函数使用平方损失
平方损失函数有许多友好的地方,它具有一阶项(通常称为残差)和二次项。对于其他形式的损失函数,并不容易获得这么好的形式
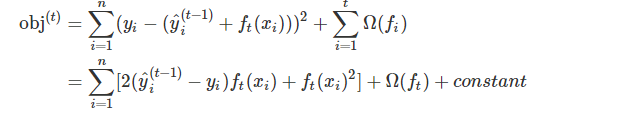
损失函数不是平方损失
泰勒二阶展开

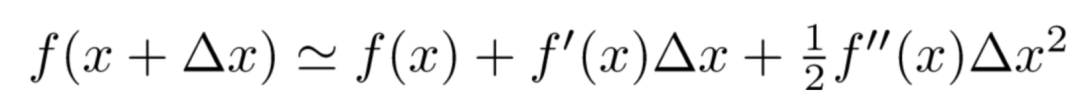

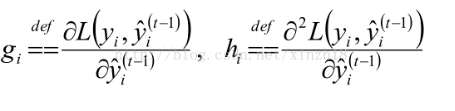
代入原公式:
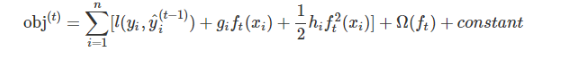
化简树结构
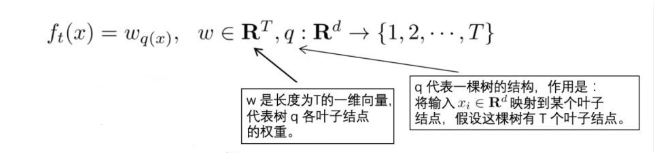
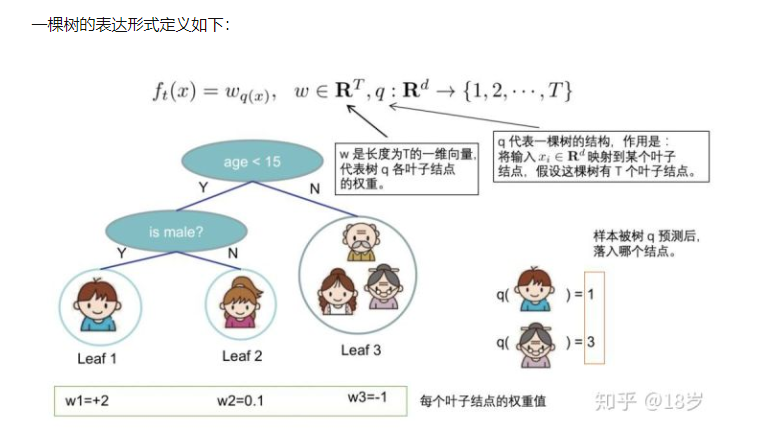
定义一棵树q(x)为输入x然后输出叶子结点索引,w为叶子结点向量
树的复杂度
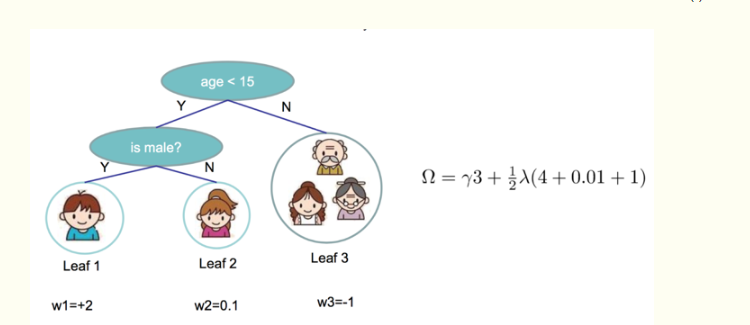
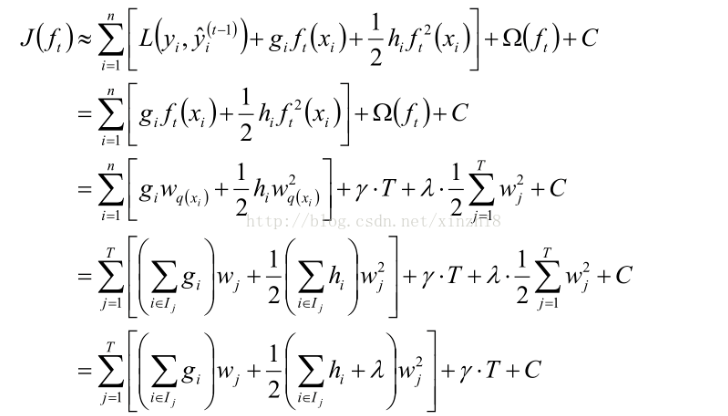
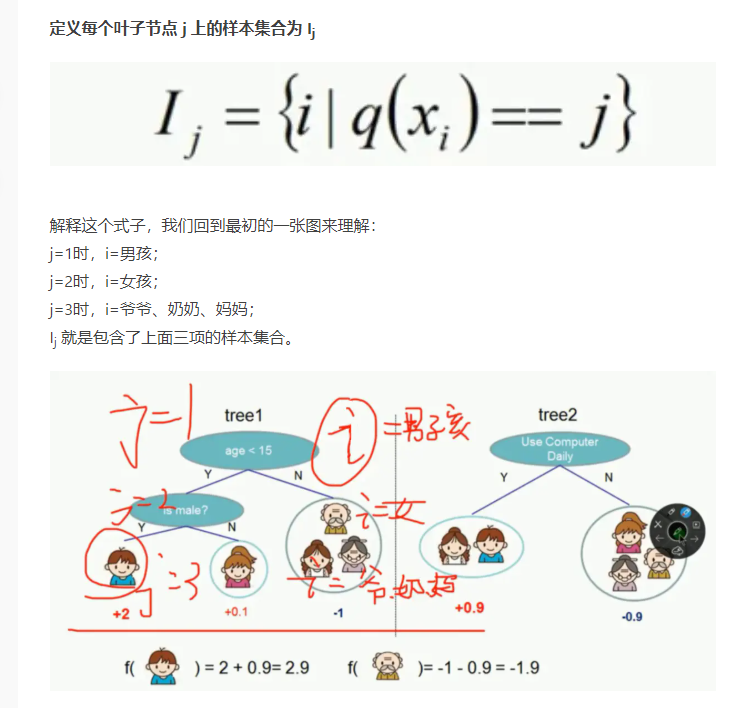

这样就将样本累加操作转换为叶子节点的操作
Gj 表示映射为叶子节点 j 的所有输入样本的一阶导之和
G和H都是常数,那么这个问题就变成了一个二次问题了,求解最小值
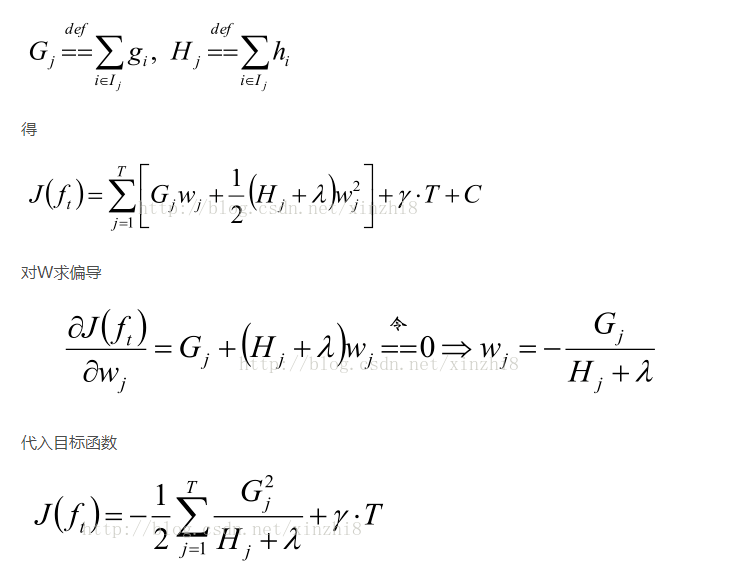
####
5.Xgboost的实现(案例:回归预测房价)
1 | train=pd.read_csv(r'C:\Users\Administrator\Desktop\train.csv', header=0) |
6.Xgboost的参数详解以及使用
一般参数:控制总体的功能
1 | 1.booster[default=gbtree]选择基分类器 gbtree、gblinear 树或线性分类器 |
Tree Booster参数:控制单个学习器的属性
1 | 1. learning_rate[default=0.3]:学习率learning rate,步长.一般常用的数值: 0.01-0.2 |
学习任务参数:控制调优的步骤
1 | 1.objective [缺省值=reg:linear] |
调参方法
1 | 需要借助一个模块sklearn.model_selection.GridSearchCV(模型调参利器,网格搜索) |
1 | import xgboost as xgb |
案例2:https://www.jianshu.com/p/7aab084b7f47
7.Xgboost的注意事项
1 | 1.windows安装推荐方式,直接pip会各种报错 |
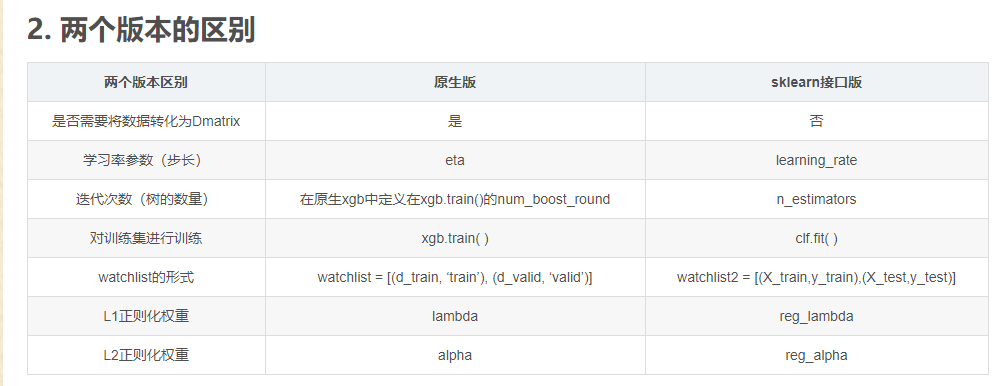
Xgboost原生接口和Sklearn接口的区别
1 | 1.xgboost原生接口,数据需要经过标签标准化(LabelEncoder().fit_transform)、输入数据标准化(xgboost.DMatrix)和输出结果反标签标准化(LabelEncoder().inverse_transform),训练调用train预测调用predict. |
xgb在选择最佳分裂点,进行枚举的时候并行!
xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行
拟合残差只是考虑到损失函数为平方损失的特殊情况,负梯度是更加广义上的拟合项,更具普适性。
无论损失函数是什么形式,每个决策树拟合的都是负梯度。准确的说,不是用负梯度代替残差,而是当损失函数是均方损失时,负梯度刚好是残差,残差只是特例。
为啥要去用梯度拟合不用残差?代价函数除了loss还有正则项,正则中有参数和变量,很多情况下只拟合残差loss变小但是正则变大,代价函数不一定就小,这时候就要用梯度啦,梯度的本质也是一种方向导数,综合了各个方向(参数)的变化,选择了一个总是最优(下降最快)的方向;