hadoop基础知识
1 | hadoop:分为1.0、2.0和3.0版本.目前企业最常见的是2.0版本. 1.0版本由hdfs和mapreduce构成,2.0在hdfs的上层添加了yarn,并且计算框架也由单一的mapreduce,添加了其他计算框架如spark,Mr等 |
hadoop API
1 | package HDFS.learnself; |
hadoop特点
1 | 1.分布式存储架构,支持海量数据(GB,PB,TB级别) |
map reduce
1 | 任务分成:map任务和reduce任务。map操作完后会进行shuffle操作,将相同key的分发到一起,同一个reduce任务中 |
Yarn架构
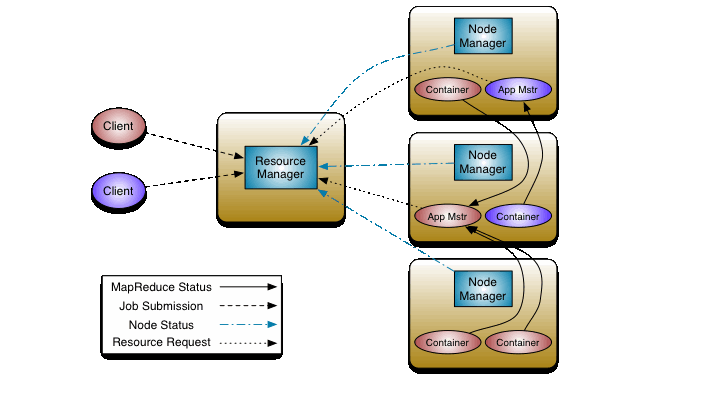
1 | yarn:是在hadoop1.0的基础上衍生出来的,为了缓解jobtracker的压力.主要进行资源调度和任务分配. |
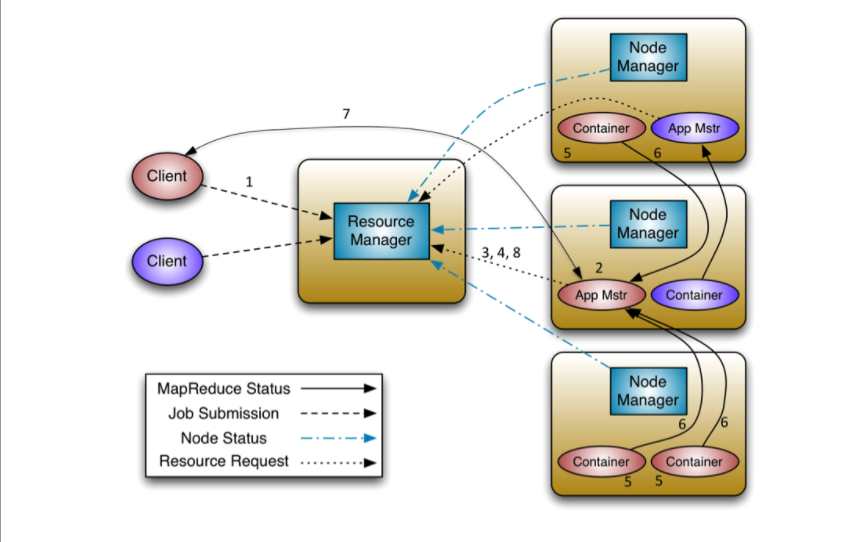
yarn的调度流程

Flume
1 | Flume:海量日志采集、聚合和传输的系统。最主要的作用是实时读取服务器本地磁盘的数据,将数据写入到HDFS中。 |
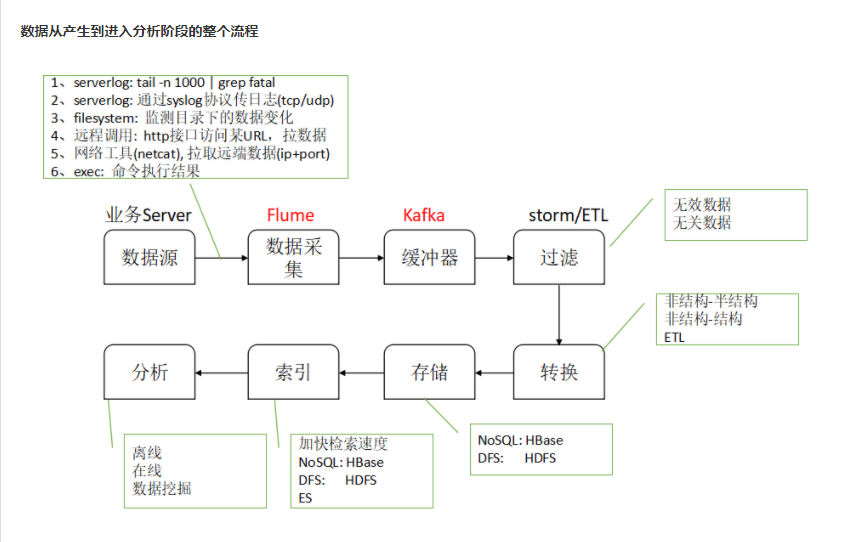
Kafka
1 | 快速了解:https://max.book118.com/html/2021/1027/8005064135004025.shtm |
hive
1 | hive是数据仓库的一种 |
sqoop既可以实现数仓到关系型数据库,也可以实现关系型数据库到数仓
大数据创建总共分成两种一种是离线批处理一种是实时处理
离线批处理流程:
1. 日志通过flume进行采集
2. 将数据存入hdfs中
3. 通过hive进行处理
1. 建立总表
4. 建立清洗表,实现etl
5. 建立业务表,清洗业务字段
6. 建立多维度表
7. sqoop将清洗完的数据导入mysql,进行可视化
####Scala
1 | 函数定义: |
spark操作
1 | val a = sc.parallelize(Array((1,"xaioming"),(2,"dsada"),(3,"sda"))) |
自定义Spark累加器
1 | package com.benying.spark |
FLUME–HIVE–KAFKA–HBASE–STORM–SPARK
zookeeper:贯穿全部